새소식
반응형
250x250
웹 최적화 : 최고의 웹 성능을 구현하기 위해 최고의 조건을 만드는 다양한 노력을 의미한다. 즉, 최고의 성능을 만드는 것이 웹을 최적화하는 방법이다. 최적화에는 크게 세 가지 방법이 있다.
Front-End 최적화 : 웹 UI/UX 관련된 최적화이다. 주로 HTML, JS, CSS, Image의 최적화를 진행한다.
최적화가 잘 되어있는 웹사이트는 브라우저에서 콘텐츠를 다운로드, 로딩, 렌더링 할 때 속도가 빨라진다.
브라우징 시간 별 콘텐츠를 볼 때 대부분의 시간은 Front-End에서 발생한다.
Front-End 최적화하는 대표적인 방법은 다음 표와 같다.
스트립트를 병합하여 브라우저의 호출 개수를 줄인다. |
도메인 수를 줄여 DNS 조회를 최소화한다. |
스크립트 크기를 최소화해 바이트 자체를 줄인다. |
DNS 정보를 미리 읽어온다. |
스크립트를 gzip* 등으로 압축하여 전달한다. |
CSS는 HTML 상단에, JS는 HTML 하단에 위치시킨다.* |
Webpack* 등으로 브라우저 이미지 형식을 최적화한다. |
page prefetching* 한다. |
이미지 손실, 무손실 압축한다. |
타사 스크립트가 웹 성능을 방해하지 않도록 조정한다. |
Cache-Control 응답헤더를 통해 브라우저 캐시를 충실히 사용한다. |
gzip : 파일 압축에 쓰이는 응용 소프트웨어이다. 브라우저가 Gzip 압축 지원을 하게되면 브라우저는 서버에게 Aceept-Encoding이라는 헤더를 통해 Gzip을 지원하는 것을 알려주게 된다. 그러면 웹서버는 이 요청을 받고 Gzip을 지원할 응답헤더에 Content-Encoding을 통해 Gizp을 지원한다는 헤더를 보내주게 된다.
Gzip이 파일을 압축해준다고 무조건 쓰는 게 좋은 건 아니다. Gzip을 압축하고 푸는 데에도 서버와 웹 브라우저에 약간의 CPU가 쓰이게 되므로 1KB~2KB 이하는 Gzip으로 압축하지 않는 것이 좋다.
Webpack : 모듈 번들링이라고 한다. HTML 파일에 들어가는 Javascript 파일들을 하나의 Javascript 파일로 만들어주는 방식을 모듈 번들링이라고 한다. 예전에는 페이지마다 HTML을 요청해서 뿌려주는 방식이었다면 요새는 하나의 HTML 페이지에 여러 개의 Javascript 파일들이 포함되어 있다. 연관되어 있는 Javascript 종속성이 있는 파일들을 하나의 파일로 묶어줘서 관리하기 편하다.
또한 여러 모듈들의 파일을 읽어오는 데에는 시간이 오래 걸리지만 여러 파일을 하나의 파일로 번들링 해주면 더 빨리 읽어올 수 있다.
CSS, JS 선언 위치 : CSS 경우 <head> 안에 <link>를 넣는게 대부분인데 이는 페이지가 로드되면 HTML과 CSS가 동시에 파싱 되는데 HTML은 DOM을 만들고 CSS는 CSSOM을 만든다. 이 두 가지 모두 웹 사이트에서 시각적인 부분을 만드는데 필요하므로 빠른 first meaningful paint를 할 수 있게 해 줘 상단에서 선언을 해줘야 한다.
JS의 경우 <body> 태그 제일 하단에 선언문을 위치 시키는데 body 영역에 있는 HTML 코드가 먼저 실행되어 사용자의 브라우저 화면에 나타나고 스크립트 코드가 실행되기 때문에 사용자는 페이지 로딩 속도가 빠르다고 느끼게 된다.
Prefetch : 미리 불러오기 기능을 말한다. 사용자가 취할 행위 중 가장 확률이 높은 것에 대한 페이지를 미리 불러오는 것이다.
"<link rel="prefetch" href="/images/big.jpeg">" 이런 식으로 웹 페이지 내 태그를 달아 사용한다.
Back-End 최적화하는 대표적인 방법은 다음 표와 같다.
DNS* 응답이 빨라지도록 서버 증설한다. |
CDN*을 사용해 인터넷 상에 콘텐츠 캐싱한다. |
DNS 응답을 빠르게 할 수 있도록 DNS 정보를 최대한 캐싱한다. |
데이터베이스 정규화로 디스크 I/O(입출력) 최적화한다. |
웹 서버가 있는 데이터 센터의 네트워크 출력/ 대역폭을 증설한다. |
데이터베이스 캐싱으로 응답을 빠르게 한다. |
웹 서버, 웹 애플리케이션 서버의 CPU/RAM을 증설한다. |
로드밸런싱*을 통해 가장 성능이 좋은 웹 서버로 요청을 연결한다. |
프록시 서버*를 설정하여 웹 컨텐츠를 캐싱한다. |
웹 애플리케이션 로직을 가볍고 빠르게 개발한다. |
DNS : Domain Name System으로 도메인 이름(ex: www.amazon.com) 을 머신이 읽을 수 있는 IP주소 (ex: 192.0.2.44)로 변환하는 시스템
프록시 서버 : 클라이언트가 자신을 거쳐 다른 네트워크에 접속할 수 있도록 중간에서 대리해 주는 서버를 말한다.
클라이언트에서 프록시 서버로 데이터 요청 → 프록시 서버에서 다시 웹 서버로 요청 → 웹 서버에서 프록시 서버로 응답 → 프록시 서버에서 클라이언트로 응답
이렇게 하는 이유는 프록시 서버에 요청된 내용을 캐시 저장해 둔 다음 똑같은 건의 요청이 오면 서버에 따로 접속할 필요 없이 저장된 내용을 그대로 돌려주면 되기 때문에 전송시간을 절약할 수 있고 외부 트래픽을 줄임으로써 네트워크 병목 현상도 방지할 수 있다.
CDN : Content Delivery Network로 지리적으로 분산된 여러 개의 서버이다. 웹 콘텐츠를 사용자와 가까운 곳에서 전송함으로써 전송 속도를 높인다. 전 세계 데이터 센터에 파일 사본을 임시로 저장하는 캐싱이라는 프로세스를 통해 사용자가 가까운 서버에서 인터넷 콘텐츠에 접속할 수 있도록 한다. 이렇게 되면 페이지 로드 시간이 단축되고 더 빠른 고성능 웹 환경을 경험할 수 있다.
로드밸런싱 : 애플리케이션을 지원하는 리소스 풀 전체에 네트워크 트래픽을 균등하게 배포하는 방법이다. 서버 간에 로드를 균등하게 배포해서 애플리케이션 성능을 향상할 수 있고 클라이언트 요청을 지리적으로 더 가까운 서버로 리디렉션 하여 지연 시간을 단축시킬 수 있다.
프로토콜 최적화 : HTTP 프로토콜 자체의 효과를 극대화하면 콘텐츠를 최고 속도와 최저 지연 시간으로 전달할 수 있다. 즉, 프로토콜 최적화는 더 빠르게 요청하고 응답하도록 프로토콜을 업그레이드 하는 과정이다.
TCP 혼잡 제어 : TCP 네트워크의 통신량을 조절하여 TCP 네트워크가 혼잡해지지 않도록 하는 방식
TCP 혼잡 제어 기술 : 패킷을 보내는 쪽에서 네트워크에서 수용할 수 있는 양을 파악하고, 그만큼의 패킷만 보내는 약속으로 해결 가능하다. 받는 쪽은 패킷이 정상적으로 송신되었음을 알리는 ACK 패킷을 보내며 ACK 패킷을 받은 호스트는 지속적으로 패킷을 보낼 수 있다. 호스트가 네트워크의 상태를 시시각각 파악하고 전송 속도를 조절하는 것 또한 혼잡 제어 기능 중 하나이다.
느린 시작 :
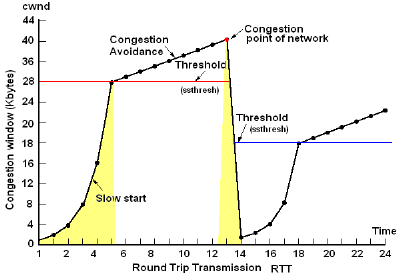
느린 시작은 전송 가능한 버퍼의 양인 혼잡 윈도우의 초깃값을 작게 설정하여 전송한다. 예를 들어 통신이 시작되면 패킷 1개만 보내고, ACK를 받으면 패킷 2배인 2개를 전송한다. 이러한 과정을 패킷 유실이 발생하기 전까지 반복하는 방식이다. ACK 응답을 받지 못하면 혼잡 윈도우의 크기는 더 이상 늘리지 않는다.
이런 식으로 네트워크에서 수용할 수 있는 혼잡 윈도우의 크기를 파악하면 그 이상의 패킷을 보내지 않는다. HTTP에서도 그대로 사용된다.
빠른 재전송 :
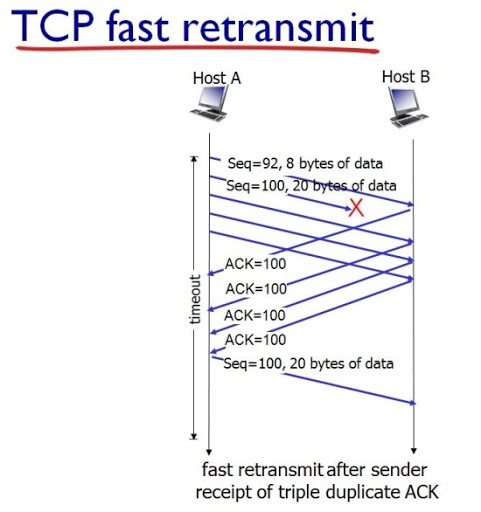
빠른 재전송은 먼저 도착해야 하는 패킷이 도착하지 않고 다음 패킷이 도착한 경우에도 수신자가 일단 ACK 패킷을 보내는 방식이다. 중간에 패킷이 하나 손실되면 송신자는 중복된 ACK 패킷을 통해 이를 감지하고 유실되었던 패킷을 재전송한다. 또한 중복된 패킷을 3개 받으면 반드시 손실된 패킷을 재전송한다.
흐름 제어 : 흐름 제어는 TCP 송신자가 너무 빠르게 혹은 너무 많은 전송을 하여 수신자의 버퍼가 오버플로우 되는 것을 방지하는 기술이다. 수신자는 수신 버퍼를 가지고 있는데 이로 인해 상위 계층으로 세그먼트를 보내는 애플리케이션 프로세스에서 데이터를 읽는 속도가 느려질 수 있다. 그러므로 송신자가 데이터를 전송하는 속도를 애플리케이션 프로세스를 읽는 속도와 유사한 수준으로 만들어야 한다.
HTTP는 텍스트 이상 콘텐츠들을 웹에서 전달하기 위해 만들어진 프로토콜로 HTTP 성능을 개선하면 웹 성능도 향상된다.
HTTP 최적화 기술
HTTP/0.9 버전 이후 HTTP/3 버전까지 HTTP는 크게 여섯 차례 업데이트가 진행되었다.
HTTP/0.9 버전까지는 클라이언트와 서버의 인터넷 통신 정상화, 가용성, 신뢰성 등 기능에 초점
HTTP/1.0 버전 부터는 클라이언트와 서버 사이 요청과 응답을 빠르게 할 수 있는 연구가 진행
웹 환경이 멀티호스트 환경으로 변하면서 HTTP/1.1 버전부터 멀티호스트 기능과 클라이언트 서버 사이에서 TCP/IP 연결을 재사용하는 기능을 추가하였다.
HTTP/1.1 버전부터 적용된 연결 재사용(persistent connection), 파이프라이닝(pipelining) 기법이 연결 기반의 HTTP 최적화 기법이다.
HTTP 연결 재사용(지속적 연결)
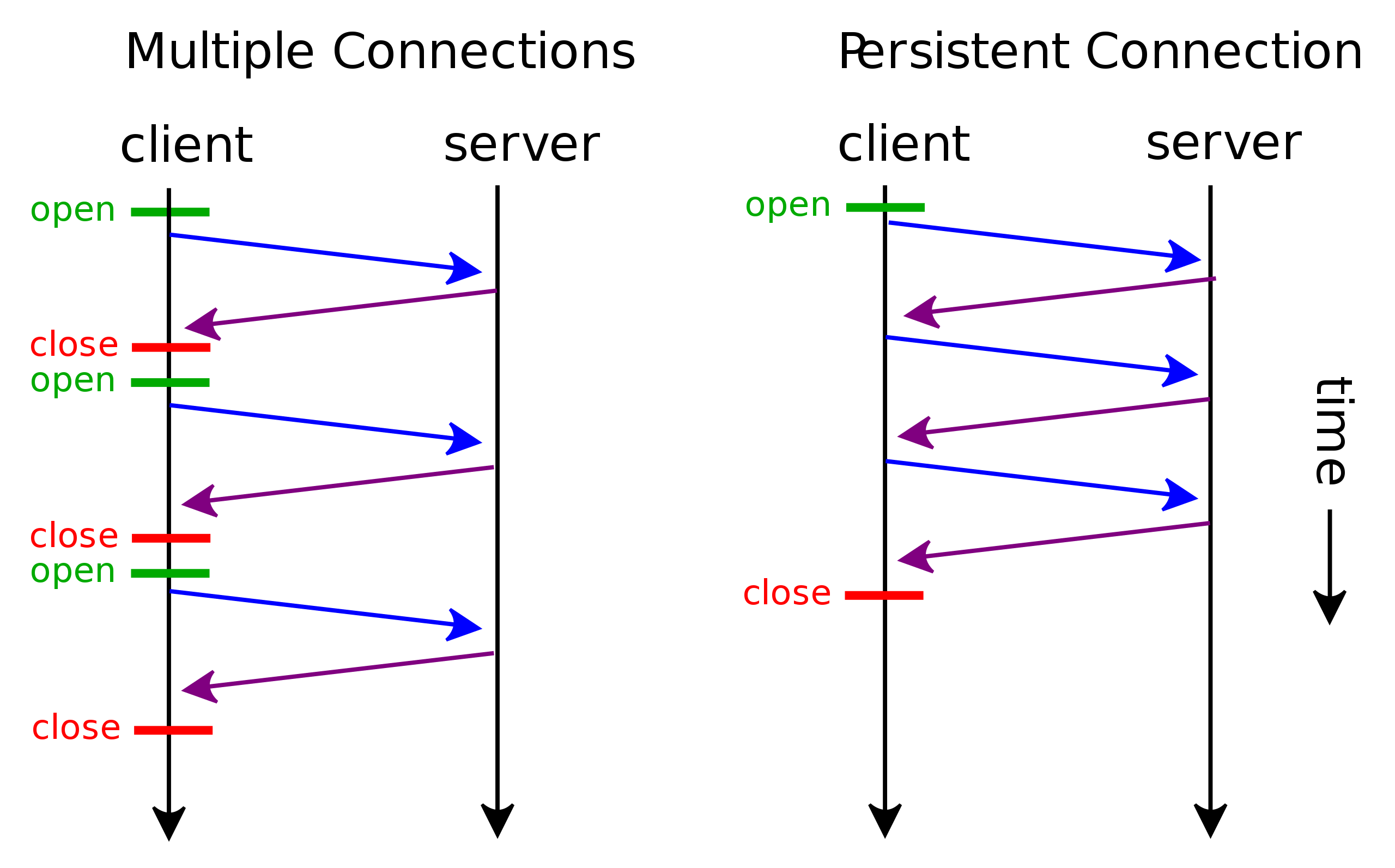
지속적 연결은 위 그림의 오른쪽처럼 TCP 상에서 한 번 연결되면 둘 사이의 연결이 완전하게 끊어지기 전까지 맺어진 연결을 지속적으로 재사용하는 기술이다.
지속적 연결 사용을 원하는 클라이언트가 해당 기능을 지원하는 웹 서버에 HTTP 요청 헤더를 이용하여 Connection 헤더 및 keep-alive 속성으로 지속적 연결을 요청할 수 있게 되었다.
이후 지속적 연결을 지원하는 서버는 클라이언트의 요청을 수용하여 동의하는 동일한 헤더를 HTTP 응답에 포함하는 것이 HTTP/1.0 RFC의 규약이 되었다.
HTTP/1.1에서는 클라이언트와 서버가 HTTP 지속적 연결 기능을 기본으로 지원하며 필요 없는 경우에만 close 요청을 통해 지속적 연결을 사용하지 않겠다고 전달한다.
HTTP 파이프라이닝
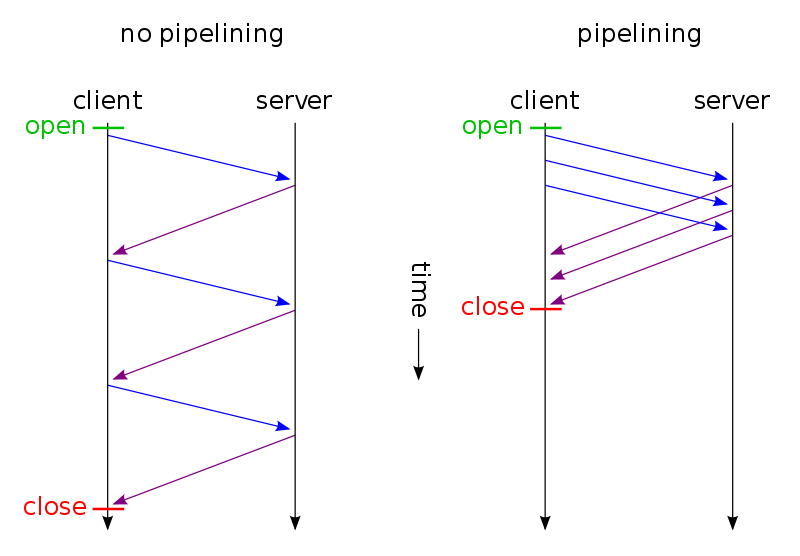
HTTP 의 선입선출(First In First Out, FIFO) 방식의 단점을 극복하는데서 출발했다.
기존에는 HTTP 요청과 응답이 여럿일 때 하나의 응답이 지연되면 나머지 요청과 응답 모두 지연될 수밖에 없었다.
HTTP 파이프라이닝은 먼저 보낸 요청의 응답이 없어도 다음 요청을 병렬적으로 수신자 측에 전송하는 기술이다.
HTTP 파이프라이닝을 사용하면 중간에 응답 지연이 발생하더라고 클라이언트는 먼저 서버 측 응답을 받을 수 있어 전체적으로 빠른 웹 로딩이 구현된다.
SQL 쿼리의 성능을 개선하기 쿼리 튜닝(query tuning)을 수행할 수 있다. 쿼리 튜닝은 쿼리가 실행될 때 일어나는 일련의 과정을 최적화하여 쿼리의 실행 속도를 높이는 것을 말한다.
쿼리 튜닝 방법
1. 인덱스 사용 : 쿼리에서 자주 참조되는 컬럼을 인덱스로 생성해서 쿼리의 성능을 개선할 수 있다.
Index는 RDBMS에서 검색 속도를 높이기 위한 기술이다.
Index를 사용하는 이유는 다음과 같다.
1. WHERE 구문과 일치하는 열을 빨리 찾기 위해.
2. 특정 열을 고려 대상에서 빨리 없애버리기 위해.
3. 조인을 실행할 때 다른 테이블에서 열을 추출하기 위해.
4. 특정하게 인덱스된 컬럼을 위한 MIN() 또는 MAX() 값을 찾기 위해.
5. 사용할 수 있는 키의 최 좌측 접두사를 가지고 정렬 및 그룹화를 하기 위해.
6. 데이터 열을 참조하지 않는 상태로 값을 추출하기 위해서 쿼리를 최적화하는 경우.
Index 작동 원리
WHERE 절에 있는 열을 찾기 위해 Index가 없으면 데이터 파일 모두를 db buffer cache로 복사한 후 하나하나 찾는다. 하지만 Index가 있는 경우에는 WHERE절의 컬럼이 index가 만들어져 있는지 확인 후 인덱스에 먼저 WHERE절에 있는 열에 대한 정보가 어떤 ROWID를 가지고 있는지 확인한 후 해당 ROWID에 있는 블록만 찾아가서 db buffer cache에 복사한다.
2. 조인 최적화 : 쿼리가 조인을 사용할 때는 조인 순서와 조인 조건을 최적화해서 쿼리의 성능을 개선할 수 있다.
A, B, C 테이블이 있다고 생각해보자. A의 PK 값과 B의 PK값을 C가 FK로 가지고 있고 각각의 FK에 대한 INDEX를 가지고 있다고 해보면 조인문은
SELECT * FROM C
LEFT JOIN A
ON C.A_ID = A.A_ID
LEFT JOIN B
ON C.B_ID = B.B_ID
이렇게 나올 것이다.
만약 SELECT * FROM A
LEFT JOIN C
ON A.A_ID = C.C_ID
의 식으로 조인을 진행하면 A 테이블은 C 테이블에는 없는 A_ID 행들을 가지고 있을 수도 있고 A 기준으로 찾는다면 A 테이블의 불필요한 정보들까지 다 찾아보게 되는 것이다.
B 테이블도 마찬가지 이므로 반대로 조회를 해야한다.
3. 서브쿼리 최적화 : 서브쿼리가 쿼리 전체의 성능에 영향을 줄 수 있기 때문에, 서브쿼리의 실행 순서를 최적화해서 쿼리의 성능을 개선할 수 있다.
서브쿼리는 쿼리 작성에 있어서는 매우 편리하지만 여러 가지 단점을 지닌다.
1. 연산 비용 추가 - 서브쿼리는 가상의 테이블을 만드는 것이다. 따라서 서브쿼리에 접근할 때마다 SELECT 구문에 접근하여 데이터를 만들고 이로 인해 연산 비용이 늘어나게 된다.
2. 최적화를 받을 수 없다 - 서브쿼리에는 메타정보가 들어있지 않다. 즉, 명시적인 제약이나 인덱스가 작성되어 있지 않다는 것이다. 이는 내부적으로 복잡한 연산을 수행하거나 결과 크기가 큰 서브쿼리를 사용할 때 성능의 문제가 발생한다.
3. 쿼리가 복잡해진다 - 쿼리가 복잡해지면 SQL 구문 전체의 가독성이 떨어지게 된다.
따라서 서브쿼리를 사용하려면 조인 시에 서브쿼리를 활용하여 결합 레코드 수를 줄여서 성능적 효율성을 높이는 방법을 쓸 수 있다.
4. 임시 테이블 최적화 : 쿼리 중간에 임시 테이블을 사용할 때는 임시 테이블의 생성과 삭제에 소요되는 시간을 최소화해서 쿼리의 성능을 개선할 수 있다.
임시 테이블도 WHERE 절로 최소화해서 사용한다.
인덱스를 활용할 수 있도록 쿼리를 짠다.
캐시에 두는 것은 8MB 미만이 되도록 한다.
5. 캐시 최적화 : 캐시 최적화는 캐시가 제공하는 성능을 최대한 활용하기 위해서 수행하는 것을 말한다. 캐시 최적화를 위해서는 캐시 구조, 캐시 저장 정책, 캐시 재사용 정책 등을 적절히 설정해야 한다.
DB 캐싱을 사용하는 이유 : 빈번하게 호출된다, 클라이언트에게 전달하는 값이 높은 확률로 동일하다, 한 번 처리할 떄 많은 DB 리소스를 이용한다.
DB 캐싱은 처음 쿼리를 전송할 때 DB에서 직접 가져온 다음 캐시에 저장한 뒤 그 다음 쿼리부터는 DB에서 가져오는 것이 아닌 캐시에 저장된 데이터를 가져와 DB 트래픽을 줄이는 것이다. 주로 DB 캐싱에는 메모리 기반의 NOSQL류의 Redis나 Memcached를 사용한다. 둘의 큰 차이점은 Redis는 단일 쓰레드로 동작한다는 것이고 Memcached는 멀티 쓰레드로 동작한다는 점이다.
DB의 트래픽을 줄이고 DB가 아닌 캐시에서 데이터를 뽑아올 수 있으므로 성능이 향상될 수 있다.
| Springboot 3.0 이상에서 Spring security 사용 (0) | 2024.01.17 |
|---|---|
| 신입 개발자의 기록 [12/06] Apache와 Tomcat을 사용해 war 배포 (1) | 2023.12.06 |
| 신입 개발자의 기록 [11/29 ~ 12/04] (1) | 2023.12.04 |
| 신입 개발자의 기록 [11/24 ~ 11/28] (0) | 2023.12.01 |
| 신입 개발자의 기록[11/21 ~ 11/23] (2) | 2023.12.01 |
소중한 공감 감사합니다